

Learn how to create natural-sounding synthetic voices with ai text to speech voice training. Master the tools and techniques to develop high-quality digital voice outputs.
AI text to speech (TTS) is getting better fast, and thanks to AI text to speech training, computers are getting really good at talking to us and reading our stuff out loud. These computer voices are everywhere in 2025 – they’re reading audiobooks, speaking in podcasts, talking in video games, and even showing up in TV shows. The best part? They sound so natural that it’s easy to listen to them, and they help create content much faster than before.
Behind the scenes, clever computer programs look at written words and figure out how to say them like a real person would. As people got better at AI text to speech training and teaching computers new tricks, these voices went from sounding like robots to sounding just like us – they can even copy the way we change our voice when we’re happy or sad.
Want to learn how to make these AI voices work for you? This guide breaks it down step by step. We’ll show you the basics of how it all works and share the newest ways to make AI voices sound just like real people. By the time you’re done reading, you’ll know exactly how to use these AI voices to make your projects better in 2025.

What You Need to Know:
The best AI text to speech training happens when we understand these main points:
- AI voices are everywhere now – they help make things like podcasts, videos, and books faster and cheaper than ever before
- Computer voices used to sound like robots, but now they sound way more natural thanks to smart technology that learns from real people’s voices
- These new AI voices are making video games more fun, TV shows more interesting, and learning easier because they sound so real
- In 2025, these computer voices can speak tons of different languages and even show feelings in their voice, just like we do
- We need to be careful how we use these voices – it’s important to be honest about when we’re using AI voices and make sure everyone can understand them
AI Text to Speech Technology
AI text to speech training is helping computers talk more like real people. Think of it like teaching a computer to read out loud – it looks at words and turns them into speech that sounds natural. These new computer voices are so good that lots of businesses are starting to use them.
Basic Components of TTS Systems
TTS systems have key parts that work together. They start by breaking down the text into smaller parts. Then, they look at each part’s role in the sentence. After that, they turn these parts into sounds that we can hear.
Evolution of Speech Synthesis Technology
Speech synthesis technology has come a long way. Old TTS engines sounded robotic, but now they sound more natural. Thanks to AI, we get voices that sound like real people.
Current State of Voice AI Technology
Voice AI technology is amazing today. Models like VITS use special tools to make voices sound better. They can even mimic the way humans speak, making our interactions with tech smoother.

“Text-to-speech AI has revolutionized the way we interact with technology, making content more accessible and communication more efficient.”
Getting Ready for AI Text to Speech Training:
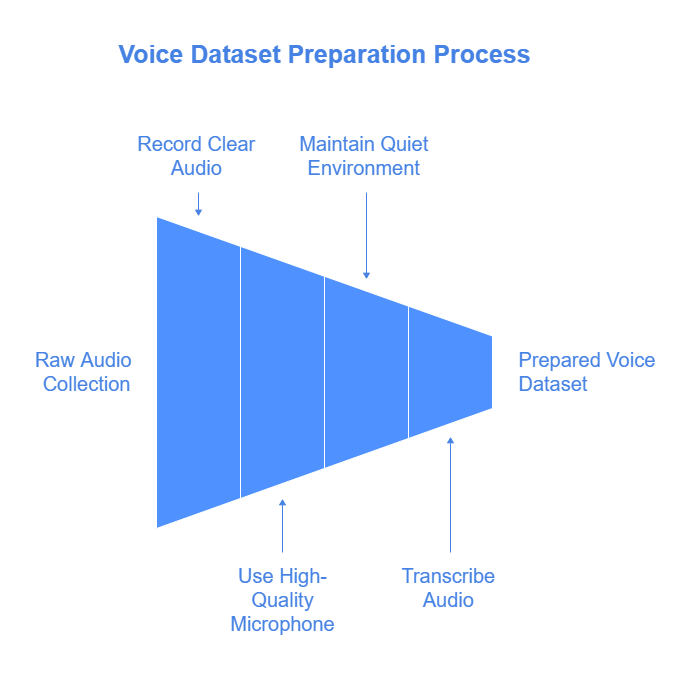
Making an AI voice that sounds good isn’t just about knowing computers – you need to plan things right and have good materials to work with. The most important thing is having lots of good voice recordings that you can use to teach the AI.
To get started with AI voices, here’s what you need: First, collect about 1-2 hours of someone talking. Then, cut these recordings into small pieces – each about 5-10 seconds long. Make sure all your recordings are saved in WAV format (that’s just a type of sound file), using one speaker at a time, and at the right volume so everything’s clear.
You’ll also need to write down exactly what’s being said in each recording – kind of like subtitles. Keep all your files organized in folders that make sense. This helps when you’re teaching multiple AI voices or trying to copy someone’s voice style.

Setting up your training space is also important. Use strong tools like Google Colab, PyCharm, Anaconda, or VSCode. With the right tools and a well-organized dataset, you can make an AI voice that will impress your audience.
AI Text to Speech Voice Training: Step-by-Step Process
Learning AI text to speech voice training is key for making top-notch speech. It starts with preparing your dataset, recording voices, and formatting data. This ensures your AI voice model trains well.
Dataset Preparation Techniques
Quality and variety in your dataset are vital. Start by gathering lots of audio samples. Make sure they’re of good quality and the right length. Then, organize your files neatly and pair each audio with a transcript.
Voice Recording Requirements
- Use a high-quality microphone for clear audio.
- Keep the recording area quiet for best sound.
- Speak the same way in all recordings.
Data Formatting Guidelines
- Your transcript should match each audio recording line for line.
- Keep your audio files in an easy-to-navigate folder structure.
- Check that your audio meets the needed sampling rate, bit depth, and format.
By carefully following these steps, you’re ready for a successful ai text to speech voice training journey. This will help you create expressive speech synthesis and voice style transfer abilities.

Selecting the Right Voice Training Model
Choosing the right voice training model is key for AI text-to-speech success. Models like VITS offer pre-configured vocoders and quick training. Others, like GlowTTS, might need extra vocoder setup. Pick based on voice quality, computer power, and project needs.
Some models work best for many voices or changing voice styles. A study in Frontiers In Neurorobotics found that robotic voices that sound human make learning better. This means picking an AI voice that sounds natural is vital for good text-to-speech videos.
The text to speech software market grew from $2 billion in 2020 to $6 billion by 2026. This shows a big demand for AI voices. Choosing the right model is very important for businesses and creators.
“TTS generators with voices closely resembling human speech are perceived as more likable.”
AI voice generation costs vary a lot, from $44 a month to $40,000 a year. This high cost means you need to train and improve the voice a lot to get it right.
For a 750-word article, hiring a voice actor costs about $749. Podcast teams can cost $1,000 to $15,000 per episode. While AI voices are fast, human voices bring relatability and personality that AI can’t match.

Choosing the right voice model for your AI project is a big decision. It’s about balancing cost, voice quality, and what your audience needs.
Voice Dataset Collection and Preparation
Creating a top-notch ai text to speech voice dataset is key. The quality and how you organize your dataset greatly affect your model’s performance. Let’s look at the best ways to collect and prepare your voice dataset.
Audio Quality Standards
For the best voice dataset, record high-quality audio. Aim for a sampling rate of at least 44.1 kHz for clear audio. Also, make sure the audio is clean, without background noise or distortions, with a signal-to-noise ratio of at least 35 dB.
Transcript Generation Methods
You’ll also need accurate transcripts for your dataset. You can do this by hand or with tools like Google Speech-to-Text. Make sure the transcripts match the audio perfectly, with correct spelling and punctuation.
File Organization Best Practices
Organizing your dataset is vital for training and managing it. Use a clear folder system with easy-to-follow names for your files. Pair each audio file with its transcript, using unique filenames for easy tracking. Aim for 1-2 hours of audio, cut into 5-10 second clips for the best training.

By following these steps, you’ll make sure your ai text to speech voice training goes smoothly. This will help your speech synthesis models reach their full capability.
Training Environment Setup and Configuration
To make a great AI text to speech model, you need a good training setup. This means installing needed packages and tools for audio. It also involves setting up model-specific settings. Whether you work from home or use cloud services, setting it up right is key for top voice synthesis.
Cloud services like Google Colab make training easy and accessible. They have the tools, computing power, and teamwork features you need. Local setups, like PyCharm or Anaconda, let you customize and control your ai text to speech voice training better.
Getting your audio settings, character sets, and model hyperparameters right is vital. This focus on detail greatly improves your text-to-speech models training. It also boosts the quality and performance of your voice conversion output.
“The Azure AI Speech environment setup guide emphasizes the importance of authenticating applications to access services with environment variables.”
By following best practices and using the right tools, you can build a strong training environment. This environment is key for your ai text to speech voice training success. With the right setup, you’ll be on your way to mastering voice synthesis and unlocking AI text-to-speech technology’s full power.
Model Training and Optimization Strategies
Creating a great AI voice needs careful model tuning. You must adjust learning rates, batch sizes, and model hyperparameters. This fine-tuning is key for top-notch speech synthesis and voice style transfer.
It’s also vital to watch how the model performs. Track loss functions and check the quality of the speech. Use strategies like mixed precision training to boost efficiency and quality. This ensures your AI voice is smooth and engaging.
Parameter Tuning Techniques
Changing the learning rate and batch size can greatly improve your AI voice model. Try different settings and watch how the model reacts. This is a critical step in making your AI voice better.
Performance Monitoring Methods
Keep an eye on the model’s performance by tracking loss functions and speech quality. Regular checks help you see where to improve. This way, you can make your speech synthesis and voice style transfer even better.
“Optimizing AI voice models is a delicate balance of fine-tuning parameters and closely monitoring performance. It’s the key to unlocking the true speech synthesis, voice style transfer, and expressive speech synthesis capabilities.”
Conclusion: Advancing Your AI Voice Training Journey
Starting your AI text to speech voice training journey is exciting. It’s a path of learning and trying new things. The field has grown a lot, with better models and training methods.
Looking forward, we might see voices that sound more real and emotional. We could also see voices in more languages. And voices that sound more natural.
To keep up, it’s important to follow the latest in AI voice training. This way, you can make high-quality voices for many uses. From teaching to helping with daily tasks.
The future of AI voice training is bright. It’s full of chances to explore new things in voice synthesis. Keep learning and you’ll find new ways to use AI voices.
FAQs about Ai Text to Speech Voice Training
What are the basic components of TTS systems?
TTS systems have several parts. First, text is broken down into smaller pieces. Then, it’s analyzed and turned into sounds. These sounds are used to create speech.
How has speech synthesis technology evolved?
Speech synthesis has gotten much better. Now, AI makes speech sound more natural. New models like VITS use special techniques for better results.
What are the prerequisites for AI voice training?
To train AI voices, you need a good audio dataset. It should be 1-2 hours long, with short clips. The audio should be in WAV format and clear.
What are the key steps in the AI text-to-speech voice training process?
Training AI voices involves several steps. First, you prepare the dataset. Then, you record and format the voice. Good quality and length are key.
How do you choose the appropriate voice training model?
Choosing the right model is important. Models like VITS are good because they’re easy to use. Others, like GlowTTS, might need more setup.
What are the best practices for voice dataset collection and preparation?
For a good dataset, record clear audio. Use a high-quality microphone and keep the environment quiet. You can write transcripts by hand or use tools.
How do you set up the training environment for AI voice training?
To start training, you need the right setup. Install necessary packages and tools. You can use cloud platforms or local environments like PyCharm.
What are the key model training and optimization strategies?
Training models means adjusting settings for the best results. You can tweak learning rates and other parameters. Keep an eye on how well the speech sounds.
Source Links
- https://www.listening.com/blog/ai-voice-generator/
- https://www.respeecher.com/
- https://www.liveperson.com/blog/text-to-speech-ai/
- https://telnyx.com/resources/how-ai-voice-works
- https://www.linkedin.com/pulse/text-to-speech-ai-deep-dive-vasu-rao-mm09c
- https://wellsaidlabs.com/blog/how-to-make-ai-voice/
- https://www.uptech.team/blog/how-to-make-an-ai-voice-assistant
